Primero abrimos Access
Vamos a inicio- Todos los programas -- Microsoft Office -- Microsoft Office Access
Le damos clic.

Nos va a salir una ventana como la siguiente

Le damos clic donde dice base de datos en blanco

Y en la parte derecha no aparecerá un cuadro, en el cual colocaremos el nombre de la base de datos y le damos clic en crear. Como aparece a continuación.

Después de que le demos clic en crear nos aparecerá una ventana como la siguiente.

Listo aquí tenemos ya creada una base de datos en Access 2007.
Tutorial De Cómo Crear Tablas En Access 2007.
Después que hayamos creado la base de datos. El siguiente paso es llenarla con datos, así que a continuación vamos a crear tablas las cuales llenaremos con datos y haremos ciertas cositas con ellas. Aprenderemos a manejar las llaves primarias y relacionar las tablas entre sí.
Bueno, para crear una tabla seguiremos los siguientes pasos:
En la barra de herramienta encontraremos una opción que dice crear, le damos clic y nos aparecen otras opciones de las cuales daremos clic en tabla así como lo muestra la imagen.


Después de crear la tabla necesitamos los campos donde almacenaremos los registros. Para crear los campos le damos doble clic en la opción AGRGAR NUEVO CAMPO y (siempre por defecto a parece como tipo texto) para elegir otro tipo de dato que necesitemos hacemos lo siguiente: damos clic en TIPOS DE DATOS y escogemos el tipo que necesitemos. Esto lo hacemos con cada campo que creemos. Y procedemos a llenar los campos.

Después de darle los nombres a los campos y llenarlos con datos quedaría algo como así.

Luego de esto debemos escoger cual será nuestra llave o llaves primarias dentro de la tabla. En este caso para visualizar eso le damos clic derecho en el nombre de la tabla y escogemos la opción Vista de Diseño.

Y nos a parecerá una ventana como esta:

En este caso por defecto nuestra llave primaria es Id, pero nosotros la podemos cambiar según sea necesario para cuando almacenemos datos. Todos los datos pueden ser llaves primarias solo con seleccionar todos los campos y dar clic en Clave Principal (llave).

Después que ya manejamos lo de las llaves primarias. Algo que debemos tener muy en claro es lo de las relaciones entre tablas para eso necesitamos 2 o más tablas (en este caso deberás crear otra tabla para que puedas relacionarlas). Como a parece en la imagen, para este ejemplo cree una tabla que se llama ciudad el cual tiene los campos id – código – nombre

Para relacionarlas no vamos a la barra de herramienta en la opción HERAMIENTAS DE BASE DE DATOS – RELACIONES y le damos clic. 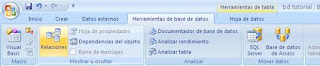

como el siguiente en donde nos muestra
Todas las tablas que hemos creado.
Las seleccionamos a todas y
le damos Agregar y cerrar.
Nos debe salir esto
En este caso voy a relacionar el campo código de la tabla ciudad con el campo ciudad de la tabla persona. Seleccionamos el campo código y arrastramos el puntero hasta el campo ciudad.
Aparecerá algo como esto. El 1 y ese símbolo de infinito quiere decir que la relación es uno a varios.
A continuación probamos a que la Integridad Referencial funcione.
Aquí les muestro los códigos permitidos en el registro.
Tutorial De Cómo Crear Consultas En Access 2007.
Nos vamos a la barra de herramienta a la opción crear como antes y damos clic en diseño de consulta.

la parte superior donde dice Consulta 1 y le
damos en la opción guardar, colocamos el nombre y aceptamos.
Después que seleccionemos las tablas, escogemos los campos a los cuales haremos las consultas. Dos opciones seleccionamos el campo y lo arrastramos hacia las celdas de abajo o en las mismas celdas escogemos la opción donde dice campo y escogemos el campo a el cual le haremos la consulta.

Con esto terminamos todo lo relacionado con las tablas…
Tutorial De Cómo Crear Formularios En Access 2007.
Para crear Formularios nos vamos de nuevo a la barra de herramienta a la opción Crear – Asistente para formularios. (Esta es una de las formas más sencillas de crear formularios)

Luego de escoger damos clic en siguiente.
A continuación nos muestra otra ventana en donde nos pide que estilo queremos para nuestro formulario. Aquí podemos elegir la que más nos guste. Y le damos clic en siguiente.
Luego de escoger la opción le damos clic finalizar
Tutorial De Cómo Crear Informes En Access 2007.
Otra facilidad que nos regala Access es la de los informes. Aquí aprenderemos como crear reportes de una manera sencilla. Como lo que hemos venido haciendo nos vamos la barra de herramientas la opción crear – asistente para informes.

Le damos clic y nos aparece una ventana que nos pedirá, así como aprendimos en el tutorial para formulario, la tabla y/o consulta de la cual vamos hacer el informe.
Del lado izquierdo nos aparecen los campos disponibles de la tabla y/o consulta que hayamos escogido.
Seleccionando + > nos lo llevara al otro cuadro y con esto le estamos diciendo que nos muestre en el informe solo los campos que estén en ese cuadro.
Y le damos clic en siguiente.
Nos aparece este cuadro preguntando cual es el nivel de agrupamiento que deseamos, para esto solo le damos en siguiente
Después de que hayamos escogido le damos clic en siguiente.
En el siguiente cuadro nos preguntara la distribución y la orientación de los datos. (Se escoge de acuerdo al informe que estemos creando, para este caso los valores que tenemos seleccionados)
Y le damos clic en siguiente.
En el siguiente cuadro nos pide que escojamos el estilo del informe que deseamos. (Se escoge al gusto) Clic en siguiente.
Después de escogida una opción le damos clic en finalizar.
Nos debe aparecer algo como lo siguiente y en ese momento está hecho el informe.

Bueno y eso es todo con lo anterior aprendimos a crear una base de datos, tablas, llenar las tablas, llaves primarias, consultas, formularios e informes. Espero que le haya resuelto las dudas con respecto estos temas.